
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- MSE
- Hypothesis
- BAEKJOON
- Cross entropy
- 백준
- 강의정리
- 파이토치
- 딥러닝
- machine learning
- tensorflow
- AI
- Natural Language Processing with PyTorch
- 자연어처리
- Softmax
- DynamicProgramming
- 알고리즘
- 파이썬
- Deep learning
- Python
- 머신러닝
- rnn
- 머신러닝 기초
- DP
- 홍콩과기대김성훈교수
- classifier
- 스택
- pytorch
- 강의자료
- 정렬
- loss
- Today
- Total
개발자의시작
[머신러닝][딥러닝] Linear Regression(선형 회귀)의 Hypothesis 와 cost 2.0 본문
[머신러닝][딥러닝] Linear Regression(선형 회귀)의 Hypothesis 와 cost 2.0
LNLP 2020. 4. 8. 17:41이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다.
강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다.
링크 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io
Predicting exam score: regression
| x(hours) | y(score) |
| 10 | 90 |
| 9 | 80 |
| 3 | 50 |
| 2 | 30 |
위와 같은 데이터가 주어지고 이를 지도 학습한다고 가정한다.
여기서 y(출력)의 경우 0~100 사이의 값을 갖게 된다. 이와 같이 일정 범위 값을 예측하는 것을 지도 학습 중에서도 Regression(회귀)라고 한다.
공부한 시간 x(hour) 만큼 공부한 학생들이 점수 y(score) 의 성적을 받는다. 이 데이터가 학습 데이터가 되어 regression 모델에 입력으로 사용된다. 이제 새로운 데이터가 들어온다. 7시간 공부한 학생이 있는데 과연 점수는 몇 점을 받을까? 학습 데이터를 사용하여 학습이 완료된 regression 모델이 입력 7(x)을 받아 점수 y를 예측한다.

regression

데이터를 위와 같이 그래프로 표현할 수 있다.
(Linear) Hypothesis
Regression 모델을 학습하는 것은 하나의 가설을 세울 필요가 있다.
- 데이터에 Linear(선형) 가설을 데이터에 적용할 수 있다.
예) 공부를 많이 하면 성적이 오른다, 키가 크면 몸무게가 많이 나갈 것이다 등.
즉, regression모델의 학습은 데이터에 적합한 선을 찾는 것이다.

가설을 세우기 위해 다음과 같은 식을 사용할 수 있다.
H(x) = Wx + b
W와 b의 값에 따라 위의 그림 에서 볼 수 있듯 다양한 선을 그릴 수 있다.
모델은 학습에 사용된 데이터에 따라 적합한 W와 b를 찾는 것을 목표로 한다.
어떤 가설이 가장 좋은 가?

좋은 가설(Hypothesis)는 실제 값과 차이가 적은 가설이 좋은 가설이다 -> 데이터를 잘 학습하였다.
어떻게 데이터에 맞는 가설을 찾는가?
Cost function
- Loss function이라고도 하며 가설과 실제 데이터 값 과의 차이가 얼마나 나는지 계산.
1) H(x) - y
- 1) 수식을 계산하면 가설과 실제 값과의 차이를 계산할 수 있다. 하지만 실제 값이 더 큰 값인 경우 H(x) - y 의 결과는 음수가 되게 된다. 예를 들어 위의 그림에서 나타난 가설과 데이터의 차이는 다음과 같다.
Loss = ( 1.2 - 1 ) + ( 1.8 - 2 ) + ( 2 - 3) = -1
실제 값과 가설의 차이에 대한 합을 구하면 음수 값과 양수 값이 공존하기에 정확한 측정이 불가능 하다.
2) ( H(x) - y )^2
- 1) 번 방법에서 발생하는 문제를 해결하기 위해 1)식에 제곱을 취한 결과를 사용한다. 제곱을 취했을때의 차이는 아래와 같다.
Loss = ( 1.2 - 1 )^2 + ( 1.8 - 2 )^2 + ( 2 - 3 )^2
결과는 모든 차이가 양수로 나타나며 이 값을 모두 더하면 차이를 알 수 있다. 따라서 차이(cost)를 구하기 위해 이와 같은 수식을 사용한다. 이 식을 오차 제곱 평균이라 하며 cost function으로 사용한다.
수식을 다시한번 formal 하게 정리하면 아래와 같다.


이를 일반화 하면 다음과 같이 쓸 수 있다.


따라서 Linear Regression의 학습은 cost의 값을 최소로 하는 W와 b를 찾는 것을 목표로 한다.
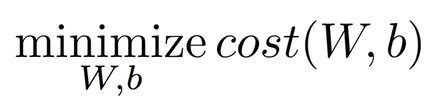
오류 또는 이상한 점 있다면 댓글로 남겨주시기 바랍니다.
감사합니다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [머신러닝][딥러닝] Linear Regression의 cost 최소화 minimize cost 3.0 (0) | 2020.04.23 |
|---|---|
| [머신러닝][딥러닝] TensorFlow로 간단한 linear regression 구현 2.1 (0) | 2020.04.08 |
| [머신러닝][딥러닝] 에이다부스트(Adaboost) 개념 정리 (0) | 2020.04.08 |
| [머신러닝][딥러닝] TensorFlow 설치 및 기본 동작 1.1 (0) | 2020.04.08 |
| [머신러닝][딥러닝] 기본 머신러닝 개념 및 용어 1.0 (0) | 2020.04.07 |



