
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MSE
- DP
- 머신러닝
- Cross entropy
- 정렬
- 파이토치
- 스택
- 홍콩과기대김성훈교수
- 딥러닝
- Deep learning
- 자연어처리
- 백준
- 파이썬
- pytorch
- Python
- rnn
- classifier
- loss
- BAEKJOON
- AI
- DynamicProgramming
- tensorflow
- 강의정리
- 강의자료
- 머신러닝 기초
- Natural Language Processing with PyTorch
- Hypothesis
- Softmax
- machine learning
- 알고리즘
- Today
- Total
목록머신러닝 (7)
개발자의시작
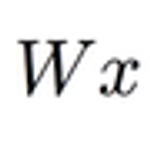 [머신러닝][딥러닝] Linear Regression의 cost 최소화 minimize cost 3.0
[머신러닝][딥러닝] Linear Regression의 cost 최소화 minimize cost 3.0
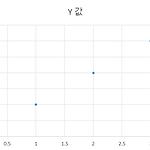
이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다. 강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다. 링크 : http://hunkim.github.io/ml/ 모두를 위한 머신러닝/딥러닝 강의 hunkim.github.io Hypothesis and cost 이전 포스팅에서 hypothesis와 cost를 다음과 같이 정의하였다. 편의를 위해 아래와 같이 표현할 수 있다. 데이터가 주어질때 Hypothesis의 W와 Cost는 다음과 같이 계산할 수 있다. X Y 1 1 2 2 3 3 W=1, cost(W)=0 W=0, cost(W)=4.67 W=2, cost(W)=4.67 Cost function을 그래프로 나타내면 아래와 같은 그림을 그릴 수 있다. 목표는 오차(c..
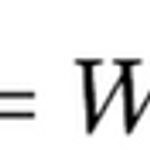 [머신러닝][딥러닝] TensorFlow로 간단한 linear regression 구현 2.1
[머신러닝][딥러닝] TensorFlow로 간단한 linear regression 구현 2.1
이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다. 강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다. 링크 : http://hunkim.github.io/ml/ 모두를 위한 머신러닝/딥러닝 강의 hunkim.github.io 이전 강의 review 강의 2.0에서 언급했듯 Linear Regression의 목표는 가설(Hypothesis)과 실제의 차이(Loss)를 줄여가는 것. TensorFlow의 메커니즘은 아래의 3가지 스텝으로 이루어짐. 1) 텐서 플로우 툴을 이용해서 그래프 빌드 2) sess.run(op)를 이용해 그래프를 실행 3) 그래프 속에 있는 값들이 업데이트되거나 값을 리턴 강의 1.1에서 배운 가설에 대한 실제 구현을 정리 1 2 3 4 5 6 7 ..
 [머신러닝][딥러닝] Linear Regression(선형 회귀)의 Hypothesis 와 cost 2.0
[머신러닝][딥러닝] Linear Regression(선형 회귀)의 Hypothesis 와 cost 2.0
이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다. 강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다. 링크 : http://hunkim.github.io/ml/ 모두를 위한 머신러닝/딥러닝 강의 hunkim.github.io Predicting exam score: regression x(hours) y(score) 10 90 9 80 3 50 2 30 위와 같은 데이터가 주어지고 이를 지도 학습한다고 가정한다. 여기서 y(출력)의 경우 0~100 사이의 값을 갖게 된다. 이와 같이 일정 범위 값을 예측하는 것을 지도 학습 중에서도 Regression(회귀)라고 한다. 공부한 시간 x(hour) 만큼 공부한 학생들이 점수 y(score) 의 성적을 받는다. 이 데이터가 ..
 [머신러닝][딥러닝] 에이다부스트(Adaboost) 개념 정리
[머신러닝][딥러닝] 에이다부스트(Adaboost) 개념 정리
이 글은 머신러닝에서 사용되는 에이다부스트(Adaboost)알고리즘에 대해 정리한 글입니다. 에이다부스트를 이해하기 위해 먼저 간단하게 기계학습(machine learning)과 부스트(boost)에 대해 짚고 넘어갈 필요가 있습니다. 기계학습 (machine learning) - 프로그램이 주어진 데이터를 스스로 학습하여 정보를 얻거나 예측 및 분석하는 것. 기계학습 중 지도 학습(supervised learning)은 크게 두 단계로 이루어져 있습니다. 1) 주어진 데이터로 학습하여 특징 추출(feature extraction) 2) 특징을 이용하여 분류(classification) 부스팅(boosting) - 예측 성능이 낮은 약한 분류기(weak classfier)들을 활용하여 조금 더 좋은 성능..
 [머신러닝][딥러닝] TensorFlow 설치 및 기본 동작 1.1
[머신러닝][딥러닝] TensorFlow 설치 및 기본 동작 1.1
이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다. 강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다. 링크 : http://hunkim.github.io/ml/ 모두를 위한 머신러닝/딥러닝 강의 hunkim.github.io TensorFlow 설치는 아래의 링크에서 할 수 있습니다. 링크 : https://www.tensorflow.org/ TensorFlow An end-to-end open source machine learning platform for everyone. Discover TensorFlow's flexible ecosystem of tools, libraries and community resources. www.tensorflow.org 텐서 플..
이 글은 홍콩과기대 김성훈 교수님의 강의를 개인적으로 정리한 글입니다. 강의 영상 및 강의자료는 아래의 링크에서 확인하실 수 있습니다. 링크 : http://hunkim.github.io/ml/ 모두를 위한 머신러닝/딥러닝 강의 hunkim.github.io 지도 학습 vs 비지도 학습 머신러닝은 크게 지도 학습과 비지도 학습 두 가지로 나뉜다 지도 학습(supervised learning) 지도 학습은 정해져 있는 데이터를 학습하는 것(learning with labeled example) 즉, 이미 답(label)이 정해져 있는 것을 학습하는 것을 지도 학습이라 한다. 여기서 답(label)이 붙여진 데이터들이 학습에 사용되는 학습 데이터(training data)가 된다. 예) 동물 그림들을 보고 ..
 머신러닝(Machine Learning)과 딥러닝(Deep Learning)의 차이. [딥러닝][머신러닝][기계학습][심층학습][인공지능]
머신러닝(Machine Learning)과 딥러닝(Deep Learning)의 차이. [딥러닝][머신러닝][기계학습][심층학습][인공지능]
인공지능(AI)에 대한 관심이 날이 갈수록 커지고 있다. 인공지능이란 말을 언론이나 매체 등에서 사용할 때 머신러닝, 기계학습(Machine Learning)과 딥러닝(Deep Learning)이라는 단어가 동반되는 것을 자주 볼 수 있다. 머신러닝과 딥러닝이 인공지능의 하위 개념 정도로 알고 있지만 이 포스팅에서는 구체적인 예와 함께 그 차이를 정리해 본다. 1. 인공지능, 머신러닝, 딥러닝의 상관관계 먼저 인공지능, 머신러닝, 딥러닝의 상관관계는 위와 같습니다. 흔히 사용하는 인공지능(AI:Artificial Intelligence)가 가장 큰 범주이며, 머신러닝 딥러닝 순으로 작은 범주에 속하게 됩니다. 2. 머신러닝, 기계학습(Machine Learning) 머신러닝, 즉 기계학습은 주어진 데이터..