
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Hypothesis
- classifier
- 머신러닝
- 알고리즘
- DynamicProgramming
- DP
- 정렬
- 딥러닝
- 머신러닝 기초
- rnn
- pytorch
- 파이토치
- 강의정리
- 파이썬
- Natural Language Processing with PyTorch
- 홍콩과기대김성훈교수
- Cross entropy
- tensorflow
- AI
- Softmax
- loss
- Deep learning
- 자연어처리
- 강의자료
- machine learning
- 백준
- Python
- 스택
- MSE
- BAEKJOON
- Today
- Total
개발자의시작
[Pytorch] 07-2 MNIST Introduction 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이 chapter에서는 다음의 주제를 다룬다.
What is MNIST?
Code: MNIST Classifier

MNIST는 손으로 쓰인 데이터 셋이다. 그림과 같이 0에서부터 9까지 숫자 이미지로 구성되어있다. MNIST 데이터셋이 이 만들어진 이유는 예전에 우체국에서 우편번호를 자동으로 인식하기 위해 고안되었다. MNIST 데이터셋은 다음과 같이 train set과 test set으로 구성되어 있다.

MNIST 데이터셋에 대해 조금 더 자세히 살펴본다. 그림은 실제 MNIST 데이터셋에 있는 샘플 중 하나이고 숫자 7에 해당하는 이미지이다. MNIST는 28x28 해상도의 이미지이고 1개 channel을 가지는 gray scale 이미지이다. 즉, 28x28 값들로 이루어져 있고 이는 784개의 값들로 이루어진 데이터로 볼 수 있다. 실제 PyTorch에서는 view() 함수를 사용해서 784개 이미지로 바꿔서 사용한다.
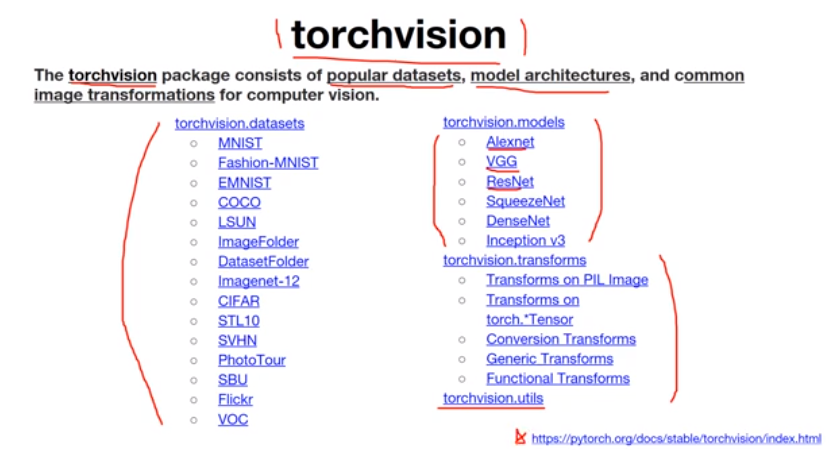
코드에 들어가기 앞서 torchvision 패키지에 대해 설명한다. torchvision은 PyTorch에서 사용하는 패키지중 하나로 유명한 데이터셋, 모델 아키텍처, 데이터에 적용할 수 있는 transform 등을 제공한다.
실제 코드와 함께 torchvision을 사용해서 어떻게 MNIST 데이터를 불러오는지 살펴본다.

torchvision.datasets을 이용해 MNIST를 불러온다. MNIST() 함수에는 4개의 인자가 있는데, "root"는 어느 경로에 MNIST 데이터가 있는지를 나타낸다. "train"은 "True"일 경우 MNIST의 train set을 False일 경우 test set을 불러온다. "transform"은 MNIST 이미지를 불러올 때 어떤 transform을 적용할지를 나타낸다. 일반적인 이미지는 0~255의 값들을 가지고 높이(H), 너비(W), 채널(C) 순서로 되어있다. PyTorch의 경우 0~1 사이의 값을 가지며 순서는 채널(C), 높이(H), 너비(W)를 가지기 때문에 transform.ToTensor() 함수를 사용하여 이미지의 값들과 순서를 PyTorch에 맞게 설정한다. "download"는 만약 root에 MNIST 데이터가 존재하지 않는다면 다운을 받는 것을 의미한다.
데이터를 DataLoader를 통해 불러올 것인데, DataLoader() 함수 역시 4개의 인자를 갖는다. "DataLoader"는 어떤 데이터를 load 할 것인지를 나타낸다. "batct_size"는 MNIST 이미지를 불러올 때 몇 개씩 잘라서 사용할지, "shuffle"은 무작위로 불러올지 입력된 순서 그대로 사용할지, "drop_last"는 batch_size만큼 잘라서 사용할 때 남는 데이터가 있다면 사용할지 아닐지를 결정한다.
for문을 사용해 data_loader를 불러오면 X에는 MNIST 이미지가, Y에는 Lable(0~9)이 저장된다. X는 view()를 이용해서 기존 (배치 사이즈 크기, 1 [채널], 28, 28)로 불러온 데이터를 (배치 사이즈 크기, 784)로 변환해 준다.

Epoch / Batch size / Iteration
- Epoch
epoch은 training set 전체가 한번 학습에 사용이 되는 것을 의미한다. MNIST의 경우 학습 데이터에서 6만 장의 사진이 사용되는데 이 6만 장이 모두 학습에 사용되면 1 epoch이 돌았다고 표현한다.
- Batch size
학습이 돌 때 training set을 한 번에 사용할 경우 6만 장의 데이터가 모두 한 번에 학습하면 메모리도 너무 많이 사용되고 학습 속도도 떨어지게 된다. 그래서 이 데이터들을 잘라서 사용할 수 있는데, 이때 잘라진 하나의 데이터 크기를 batch size라고 한다.
- Iteration
iteration은 배치를 몇 번 학습에 사용했는지에 해당한다. 예를 들어 1000개의 training set이 있을 때 batch size를 500으로 설정할 경우 2개의 batch가 존재한다. 두 개의 batch를 이용해서 2 iteration을 학습에 사용하게 되면 1 epoch이 끝났다고 볼 수 있다.
Classifier를 학습하는 방법을 자세히 살펴본다. 여기서는 softmax classifier를 사용할 것이다.

Linear layer를 하나 사용하며 입력은 784(MNIST가 28x28 =784 크기의 데이터)이고 출력은 10(MNIST가 0~9 label을 가짐), bias는 "True"로 설정하여 학습한다. cost는 CrossEntropyLoss()를 사용하며 Pytorch에서는 CrossEntropyLoss()가 softmax를 자동으로 계산해주기 때문에 별로도 선언하지 않는다. optimizer는 SGD를 사용하고 linear의 파라미터 W와 b를 인자로 사용한다.
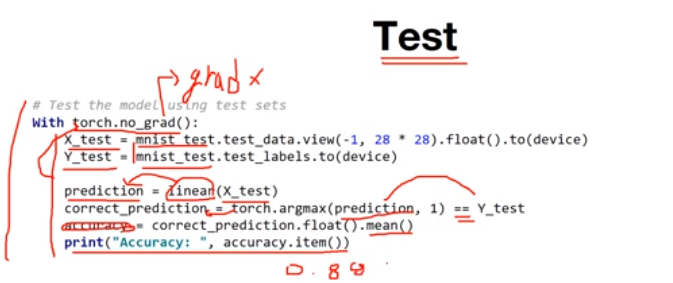
학습이 완료되면 test를 해봐야 한다. torch.no_grad()는 gradient 계산을 하지 않겠다는 의미로 test에는 가중치 업데이트를 하지 않기 때문에 시 반드시 설정해야 한다.
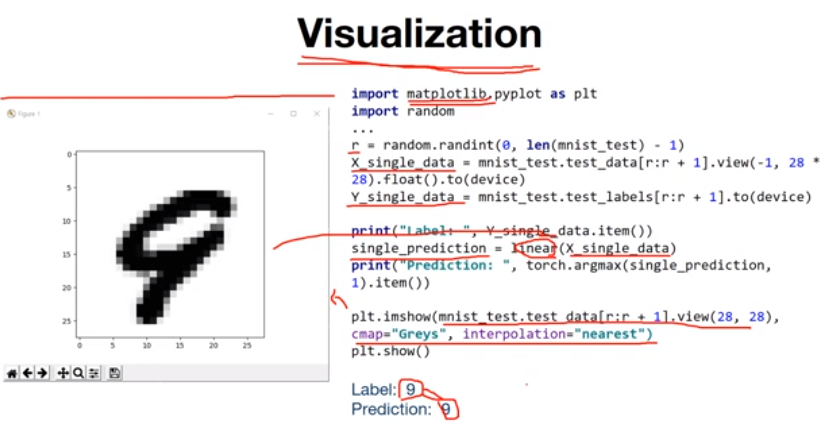
이미지를 이용하기 때문에 visualization을 적용해 눈으로 확인해본다. MNIST test data 중 무작위로 하나 뽑아서 학습한 모델에 넣어서 예측을 해보고, 예측한 이미지를 띄워보면 다음과 같이 나타낼 수 있다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 08-2 Multi Layer Perceptron (0) | 2022.01.14 |
|---|---|
| [Pytorch] 08-1 Perceptron (1) | 2022.01.14 |
| [Pytorch] 07-1 Tips (0) | 2021.12.30 |
| [Pytorch] 06-2 Softmax Classification Pytorch (0) | 2021.12.29 |
| [Pytorch] 06-1 Softmax Classification (0) | 2021.12.28 |



