
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Python
- AI
- 백준
- 정렬
- loss
- Deep learning
- pytorch
- 딥러닝
- MSE
- 파이토치
- 자연어처리
- 파이썬
- classifier
- 머신러닝
- rnn
- DynamicProgramming
- Cross entropy
- BAEKJOON
- DP
- 스택
- 홍콩과기대김성훈교수
- Hypothesis
- 강의자료
- 머신러닝 기초
- Natural Language Processing with PyTorch
- Softmax
- tensorflow
- 알고리즘
- machine learning
- 강의정리
- Today
- Total
개발자의시작
[Pytorch] 09-1 ReLU 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이 chapter에서 살펴볼 내용은 다음과 같다.
- Problem of Sigmoid
- ReLU
- Optimizer in PyTorch
- Review: MNIST
- Code: mnist_softmax
- Code: mnist_nn

sigmoid의 문제점에 대해 살펴본다. sigmoid를 activation function으로 사용하는 네트워크가 있다고 가정한다. 이를 학습시키기 위해서는 어떤 입력 데이터가 주어졌을 때 w를 곱하고 sigmoid를 activation 함수로 사용하고 output을 구하게 된다. 그 후 정답 데이터인 G와 아웃풋 O의 차이를 이용해서 cost/loss를 계산한다. Loss를 구하면 미분을 통해 gradient를 구하게 되고 이를 backpropagation 하여 w를 업데이트하여 학습을 진행한다. 여기서 sigmoid의 문제는 gradient를 계산하면서 발생한다. 그림의 아래에 있는 것은 sigmoid function을 도식화한 것으로 이때 gradient를 계산할 하면 파란색에 해당하는 부분은 문제가 없지만 양 끝인 붉은 부분은 gradient를 계산하면 0 혹은 0에 가까운 아주 작은 값을 나타내게 된다. backpropagation으로 앞단에 gradient를 넘겨줄 때 아주 작은 값이 전파되면서 소멸되는 현상이 발생한다. 이를 Vanishing Gradient(기울기 소멸)라고 한다.

한 개의 layer에서는 크게 문제가 되지 않을 수 있지만, sigmoid 함수가 사용되는 여러 layer를 쌓았을 때 아주 작은 gradient가 계속해서 곱해지게 되면 앞단에서는 gradient를 거의 전파받지 못하는 현상이 생긴다.

vanishing gradient가 발생하면 backpropagation을 적용할 때 뒷 단에서는 gradient가 잘 전달되지만, 앞으로 전달될 수 록 gradient가 점점 희미해지는 것을 볼 수 있다.
ReLU

ReLU 함수는 입력 값이 음수인 경우 0으로 출력하며, 0보다 큰 값은 자기 자신을 출력한다. 즉, 음수가 입력되면 gradient가 0이 되고 양수가 입력되면 gradient가 1이 된다. 굉장히 간단하지만 효과가 좋으며 파란색 영역에서 gradient를 계산하면 1이기 때문에 vanishing gradient 문제가 발생하지 않는다. 다만, ReLU는 음수의 입력에 대해서는 gradient가 0 이기 때문에 gradient가 사라지는 문제가 발생하기도 하지만 잘 작동되는 편이다. PyTorch에서는 torch.nn.relu() 함수를 사용하여 ReLU activation function을 사용할 수 있다. 그 외에도 PyTorch는 다양한 activation function을 제공한다.
Optimizer
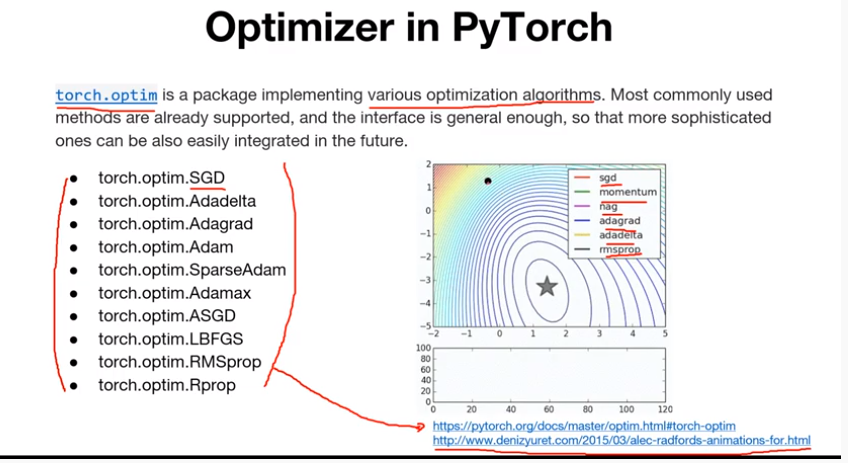
PyTorch는 다양한 optimizer를 제공한다.

각 optimizer들이 어떻게 발전했는지, 어떤 전략을 사용하는지를 나타낸다.
Code

code를 통해 살펴본다. 위의 코드는 앞서 살펴봤던 MNIST 데이터를 불러온다.

MNIST 데이터를 분류하는 classifier의 코드는 다음과 같다. 이전에 살펴본 내용과 차이점으로 optimizer가 있는데 Adam optimizer를 사용하여 classifier를 구현한다.


3개의 layer를 쌓고 ReLU() 함수를 적용한 예이다. torch.nn에 있는 Sequential 함수를 사용하며 linear3 이후에는 ReLU를 적용하지 않는데, CrossEntropy Loss를 사용하는 softmax를 적용하기 때문.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 09-3 Dropout (0) | 2022.01.17 |
|---|---|
| [Pytorch] 09-2 Weight initialization (0) | 2022.01.17 |
| [Pytorch] 08-2 Multi Layer Perceptron (0) | 2022.01.14 |
| [Pytorch] 08-1 Perceptron (1) | 2022.01.14 |
| [Pytorch] 07-2 MNIST Introduction (0) | 2022.01.14 |



