
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 강의자료
- MSE
- 파이토치
- Python
- Natural Language Processing with PyTorch
- Softmax
- DP
- 딥러닝
- tensorflow
- AI
- 홍콩과기대김성훈교수
- 정렬
- 머신러닝 기초
- 알고리즘
- Hypothesis
- BAEKJOON
- pytorch
- 파이썬
- rnn
- classifier
- machine learning
- Cross entropy
- 강의정리
- loss
- 스택
- 백준
- DynamicProgramming
- 머신러닝
- 자연어처리
- Deep learning
- Today
- Total
개발자의시작
[Pytorch] 09-3 Dropout 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
이 chapter에서 살펴볼 내용은 다음과 같다.
- Overfitting
- Dropout
- Code: mnist_nn_dropout
Overfitting

그림의 위와 같이 파란색 데이터가 주어졌다고 가정한다. 데이터를 잘 fitting 시키는 regression 모델을 학습하고자 한다. linear 한 방식으로 데이터를 fitting 시키게 되면 아래 왼쪽의 결과가 나올 것이다. 한눈에 봐도 데이터에 잘 fitting 되지 못하고 잘 표현하지 못하는 상황으로 판단된다. 다음으로 아래 가운데 곡선으로 데이터를 fiitting 시키게 되면 사람에 따르겠지만 적당히 fitting 된 것으로 판단된다. 마지막으로 아래 오른쪽과 같이 더 복잡하게 데이터에 fitting 시킬 수 도 있다. 경우에 따라 어떤 것이 더 좋을지 다르겠지만 일반적으로 왼쪽의 경우 너무 학습이 덜 됐다(underfitting), 오른쪽의 경우 너무 파란색 데이터에만 fitting 됐다(overfitting)라고 볼 수 있다. overfitting의 경우 파란색 데이터를 완벽하게 학습해냈는데 뭐가 문제인지 생각할 수 도 있는데 이는 다음에서 살펴본다.

예를 위와 같이 classification 문제로 바꿔보자. 주어진 데이터는 빨간색과 파란색으로 구성되어있고 이들을 분류하는 문제이다. train set을 기준으로 overfitting 되도록 학습을 진행했다고 가정하자. overfitting 된 분류기는 빨간색과 파란색을 완벽하게 분류하도록 학습되었다. 즉, train 도중 이 classifier는 acc가 100%에 도달했다는 의미이다. 이렇게 학습된 모델을 test set에 적용해본다. 그림의 우측과 같이 성능이 그리 좋지 못하다. 이와 같은 결과가 나타나는 이유는 train set과 test set이 완벽하게 일치하지 않기 때문이다. train set에는 굉장히 잘 훈련됐지만, 실제 test set에 적용할 때는 한 번도 보지 못한 데이터들이 들어오기 때문에 overfitting 된 모델은 에러율을 증가시킬 수 있다.

반대로 위의 가운데에 있던 적당하게 fitting 된 모델을 적용해본다. 이 경우 train 당시에는 overfitting 된 모델에 비해 낮은 성능을 보이지만, 실제 test 시에는 오히려 더 좋은 성능을 낼 수 있다.
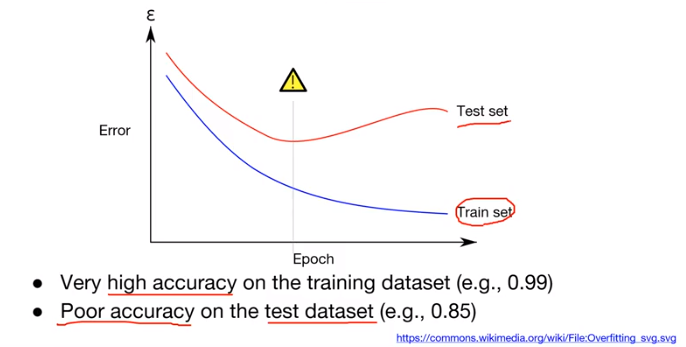
조금 다르게 정리해보면, overfitting은 train set에 대해서는 error rate이 굉장히 낮아지도록 학습이 잘 됐지만, 실제 test set에서는 acc가 떨어지고 error rate는 증가하는 것이 overfitting의 문제이다.

이런 overfitting 문제를 줄일 수 있는 방법이 여러 가지가 있다. training data를 늘린다, feature를 줄인다, regularization을 추가한다 등 다양한 방법이 있는데, 그중에서도 dropout에 대해 살펴본다.
Dropout
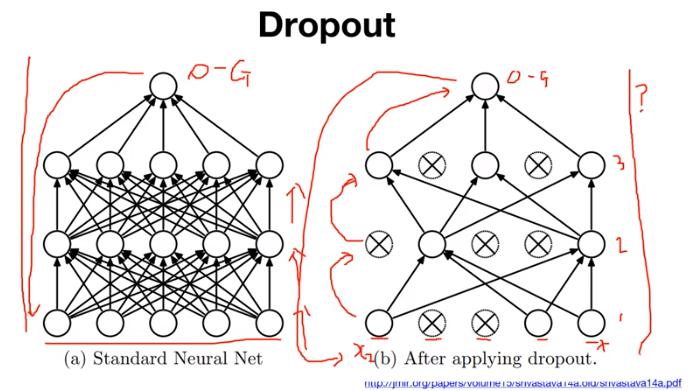
우선 좌측 그림과 같이 흔히 알고 있는 평범한 neural network에 대해 살펴본다. 학습을 할 때 학습 데이터가 입력으로 들어오면 데이터가 weight와 activation의 반복을 거쳐서 output을 만들어내고, 이 output을 truth와 비교하여 loss를 계산한 다음 backpropagation을 적용해 weight를 업데이트하는 방식이다. dropout은 우측의 그림과 같이 적용된다. dropout은 학습을 진행하면서 node들을 무작위로 껐다/켰다를 반복하는 것이다. 학습 데이터가 입력으로 들어오면 첫 번째 layer, 두 번째 layer, 세 번째 layer에서 dropout을 사용하는 상황이다. dropout의 설정된 특정 비율에 따라서 첫 번째 layer에서는 두 번째, 세 번째 노드는 사용하지 않는다. 어떤 데이터 X가 들어오면 이 데이터는 첫 번째, 네 번째, 다섯 번째 노드에 있는 weight들만 사용하여 윗 layer로 전파가 된다. 마찬가지로 두 번째, 세 번째 layer에서도 일부 노드의 weight들만 사용하여 윗 layer로 전파된다. 이후 최종 output을 구하게 되고 truth와 비교하여 backpropagation을 통해 network를 업데이트하게 된다. 그다음 step에서 마찬가지로 다른 데이터가 들어오게 되는데, 그때도 dropout은 설정된 비율에 따라 5개의 노드들 중 일부만 선택하여 다음 레이어로 전파한다. 이와 같은 dropout을 사용하게 되면 overfitting을 방지할 수 있는 효과를 얻을 수 있고 성능 향상의 효과도 얻을 수 있다. 또한, 매 학습 step 마다 사용되는 노드가 무작위로 변경되기 때문에 여러 형태의 network들이 최종 결과를 내놓는 network 앙상블의 효과를 내놓는다는 의견도 있다.
Code

dropout을 실제 PyTorch에서 어떻게 사용하고, 어떤 특징이 있는지 살펴본다. 이전 5개의 layer를 사용했던 코드와 동일한 코드를 사용한다. 거기에 torch.nn.Dropout()이라는 함수를 추가하여 사용한다. 여기서 "p"는 probability로 학습 중 전체 노드 중에서 몇% 정도를 사용하지 않을지(drop 할지)를 의미한다. 예를 들어 첫 번째 layer에서는 784개 node를 가지고 있고 p를 0.5로 설정했다면, 392개 node만을 학습에 사용하게 된다. 이후 모델을 선언할 때 "dropout"을 넣어주면 해당 layer에 dropout을 적용할 수 있다.

dropout을 사용할 때 한 가지 주의할 것이 있는데, dropout은 학습을 진행하면서 node를 사용할 것과 사용하지 않을 것을 무작위로 선별하는 것인데, 이것은 학습할 때의 방식이며 test를 할 때는 모든 node를 사용해야 한다. 그렇기 때문에 dropout을 사용할 때는 train() 모드와 eval() 모드를 주의해서 사용해야 한다. model.train() 선언 시 설정한 dropout을 적용하게 되고, model.eval() 선언 시 모델에 있는 dropout을 적용하지 않게 된다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 11-0 RNN intro (0) | 2022.03.03 |
|---|---|
| [Pytorch] 09-4 Batch Normalization (0) | 2022.03.03 |
| [Pytorch] 09-2 Weight initialization (0) | 2022.01.17 |
| [Pytorch] 09-1 ReLU (0) | 2022.01.14 |
| [Pytorch] 08-2 Multi Layer Perceptron (0) | 2022.01.14 |



