
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Cross entropy
- Softmax
- machine learning
- 머신러닝
- DynamicProgramming
- 백준
- 자연어처리
- 스택
- pytorch
- 강의자료
- Hypothesis
- 강의정리
- Deep learning
- 홍콩과기대김성훈교수
- loss
- classifier
- rnn
- 머신러닝 기초
- Natural Language Processing with PyTorch
- MSE
- tensorflow
- DP
- 딥러닝
- 파이썬
- 파이토치
- 알고리즘
- BAEKJOON
- 정렬
- Python
- AI
- Today
- Total
개발자의시작
[Pytorch] 09-2 Weight initialization 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이 chapter에서 살펴볼 내용은 다음과 같다.
- Why good iniialization?
- RBM/DBN
- Xavier/He initialization
- Code: mnist_nn_xavier
- Code: mnist_nn_deep
Initialization

위의 그래프에서 'N'이 붙은 모델들이 weight initialization 방식을 적용하여 학습을 진행한 결과이다. 그래프를 보면 'N'이 붙은 모델들이 학습이 잘되고 성능이 뛰어난 것을 볼 수 있다. 그렇기 때문에 weight를 잘 initializing 하는 것이 딥러닝의 성능에 크게 영향을 미친다는 것을 알 수 있다.

그렇다면 어떻게 initializing 할 수 있을까? 제일 간단한 방법으로는 상수로 초기화할 수 있다. 일단, 0으로 초기화하는 것은 매우 좋지 않은 방법이다. neural network를 학습할 때 backpropagation을 사용하는데 gradient를 계산하여 chain rule을 업데이트할 때 weight가 0이 되면 모든 gradient 값이 0으로 바뀌게 되어 학습을 진행할 수 없다. 그렇기 때문에 매우 어려운 일이다(Challenging issue). 2006년에 "A Fast Learning Algorithm for Deep Belief Nets" - Restricted Boltzmann Machine(RBM) 논문이 발표되었고, 이 논문의 내용은 "RBM을 이용해서 weight initialization 후 deep neural network를 학습시킨다면 성능이 올라간다"라는 내용이다.
RBM

RBM(Restricted Boltzmann Machine)은 그림과 같은 형태를 갖는다. Restricted라는 의미는 "한 layer 안에서는 연결이 없다"를 의미하고, 다른 레이어 사이에서는 각 노드들이 전부다 연결되어 있는(fully-connected) 형태를 RBM이라고 한다. 이 machine이 하는 일은 어떤 입력 X가 들어갔을 때 Y라는 것을 만들 수 있는 forward가 있고, 반대로 어떤 Y가 들어왔을 때 다시 X'을 복원할 수 있다. 각각을 일종의 encoding과 decoding으로 볼 수 있다. 그렇다면 이 RBM을 어떻게 initializing에 적용할 수 있을까? Hinton et al., (2006)은 pre-training이라는 프로세스를 제안하였다.
DBN
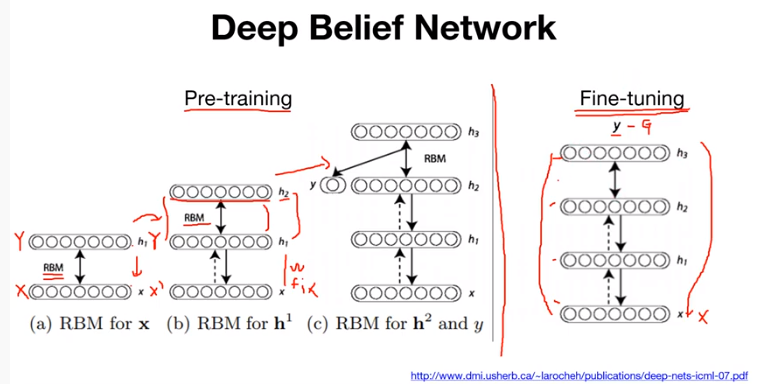
그림의 왼쪽은 Deep Belief Network에서 Pre-training step에 대한 설명이다. 처음(a)에는 두 개의 layer가 있고, 두 개의 layer를 RBM으로 학습하게 된다. RBM으로 학습한다고 하면, input X가 들어갈 때 output Y가 나오고 이 output Y를 다시 backward를 시켜서 X'으로 X를 복원할 수 있게 학습을 한다는 의미이다. 논문에서는 이 pre-training step에서 RBM을 몇 번 학습해야 하는지에 대해 연구가 되었지만 실질적으로 지금은 많이 사용되고 있지는 않다. 이렇게 2개 layer에 대해 RBM 학습이 끝나게 되면 다음 스텝(b)으로 넘어가게 된다. 다음 스텝(b)에서는 두 개 layer(a) 위에 한 개의 layer를 더 쌓게 되고 x와 h1 사이의 weight는 고정을 시켜둔다. 그 후 그 윗 layer에서만 마찬가지로 입력이 들어갔을 때 output이 나오고 output에서 backward로 복원할 수 있게 RBM 학습을 진행한다. 이 단계를 반복적으로 수행하면서 마지막 layer까지 계속해서 한 layer 씩 쌓고 RBM으로 학습하고 고정시켜놓고 한 layer 씩 쌓고 RBM으로 학습하고 고정시켜놓고를 반복한다. 이렇게 하면 pre-training 과정이 마무리된다. pre-training이 마무리된 network를 보면 RBM으로 학습된 weight들이 존재할 것이다. 그렇다면 그 weight들을 전체를 두고 일반적으로 사용하는 neural network 학습방식(input이 들어가서 Y가 나오고 G와의 차이를 계산한 다음 loss를 구해 backpropagation으로 전체 network를 업데이트하는)을 적용하게 되는데 이를 fine-tuning이라 한다. network는 RBM으로 weight가 잘 초기화되어있게 된다.

앞에서는 RBM을 이용한 weight 초기화 방식을 살펴봤는데 굉장히 복잡한 과정을 거친다. 그 후 새로운 initialization 방식들이 제안되었는데, 이런 것들은 RBM을 이용해서 pre-training 단계를 거치는 것이 아니라 간단하게 weight를 초기화할 수 있는 방법이다. 그중 대표적인 것들이 Xavier와 He initialization 방법이 있다.
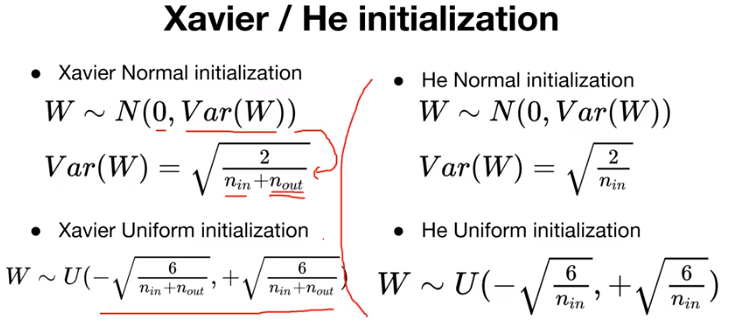
Xavier와 He initialization 은 굉장히 간단한 방법이다. RBM pre-training을 이용한 초기화 이전에는 무작위 수를 이용해서 weight를 초기화했었는데, Xavier와 He는 "layer의 특성에 따라 다르게 initialization을 해야 한다"라는 내용이다.
-Xavier
먼저 Xavier를 살펴보면 normal distribution으로 weight를 초기화하는 방식과 uniform distribution으로 weight를 초기화하는 방식이 있다. 살펴보면 normal distribution으로 초기화하는 경우에는 평균이 0, standard deviation은 수식을 이용해서 초기화하면 된다. uniform distribution도 수식을 이용해서 초기화를 하면 "잘 초기화가 된다"라는 내용이다. 앞에서 RBM을 활용해서 layer마다 학습하고 fine-tuning 하는 등의 과정 없이 매우 간단하다. 참고로 n-in은 layer의 input 수를 의미하며 n-out은 layer의 output 수를 의미한다.
-He
He initialization은 Xavier initialization의 변형이라 할 수 있으며, 마찬가지로 normal distribution으로 weight를 초기화하는 방식과 uniform distribution으로 weight를 초기화하는 방식이 있다. 수식의 형태도 비슷한데, Xavier에서 n-out term이 없어졌다고 보면 된다.
Code

PyTorch로 어떻게 initialization을 구현하는지 PyTorch package에 구현되어 있는 공식 코드를 살펴본다.

Xaiver initialization 방식을 실제 적용한 코드를 살펴본다. fully-connected 3개 ReLU를 사용했던 코드이다. 기존에는 normal distribution으로 초기화했었는데, 이를 xavier_uniform을 통해서 초기화한다. 초기화된 weight들은 그림의 아래와 같다. 결과적으로 같은 모델에서 weight initialization 방법만 바꿨는데 성능이 향상되는 것을 볼 수 있다.

조금 더 deep 하게, wide 하게 모델을 바꿔본다. 당연히 layer가 넓고 깊어졌으니까 성능이 좋아졌을 것이다. 결과적으로 학습이 잘 진행되고 성능이 약간 향상한 것을 볼 수 있다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 09-4 Batch Normalization (0) | 2022.03.03 |
|---|---|
| [Pytorch] 09-3 Dropout (0) | 2022.01.17 |
| [Pytorch] 09-1 ReLU (0) | 2022.01.14 |
| [Pytorch] 08-2 Multi Layer Perceptron (0) | 2022.01.14 |
| [Pytorch] 08-1 Perceptron (1) | 2022.01.14 |



