
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MSE
- machine learning
- 정렬
- 머신러닝 기초
- loss
- Softmax
- Hypothesis
- 백준
- 자연어처리
- Natural Language Processing with PyTorch
- 강의정리
- Cross entropy
- AI
- 알고리즘
- tensorflow
- 스택
- BAEKJOON
- 파이토치
- Deep learning
- rnn
- Python
- 강의자료
- 홍콩과기대김성훈교수
- 파이썬
- DP
- 머신러닝
- classifier
- pytorch
- DynamicProgramming
- 딥러닝
- Today
- Total
개발자의시작
[Pytorch] 11-3 RNN - longseq 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이번 chapter에서는 long sequence 코드에 대해 좀 더 알아본다.

"hihello"와 "charseq"에서는 정말 간단하고 짧은 문장이라 문장 전체를 하나의 sample로 보고 학습을 진행했는데, 사실 정말 쓸모 있는 RNN을 만들기 위해서는 긴 문장 데이터셋을 가지고 학습해야 한다. 하지만, 아주 긴 문장을 하나의 input으로 사용할 수는 없다. 그래서 "longseq"에서는 아주 긴 문장이 주어질 때 이것을 특정 사이즈로 잘라서 사용하려고 한다.
먼저 위와 같이 긴 문장이 있다고 가정한다. 최근에는 수 십 GB의 텍스트 데이터 셋으로 학습하는 큰 모델들도 있지만, 간단한 예제를 위해 위의 문장을 fixed_size_sequence로 자르고자 한다. 긴문장이 주어질 때 아래와 같이 조각조각 데이터를 만드는 것이다. sentence에 특정 size의 window가 있어서 window 만큼 X 데이터로, 한 칸씩 오른쪽으로 이동하며 정해진 window 만큼 Y 데이터로 만들어 사용한다.
long sentence를 입력으로 사용하는 코드를 살펴본다. 먼저 x 데이터와 y데이터를 담을 list를 만든다. for loop를 통해 sequence_length 만큼의 chunk를 x_str으로, 인덱스에서 1만큼 더한 위치의 문자열을 y_str이다. index로 구성된 list를 만들기 위해 char_dic을 통해 만들어 준후, 처음에 선언한 x_data와 y_data에 넣어준다. 여기까지 수행하면 원하는 chunk들이 index로 변환된 list가 만들어진다. 여기서 one-hot vector화 시켜주려면 이전 chapter에서 살펴본 np.eye()를 사용하여 one-hot vector를 만들어준다. 마지막으로 list나 numpy array로 구성된 list를 PyTorch의 Tensor type으로 바꿔준다. 이렇게 하면 sequence_length 길이만큼의 sample 들을 여러 개 만들어서 우측과 같이 x, y Tensor를 준비할 수 있다.
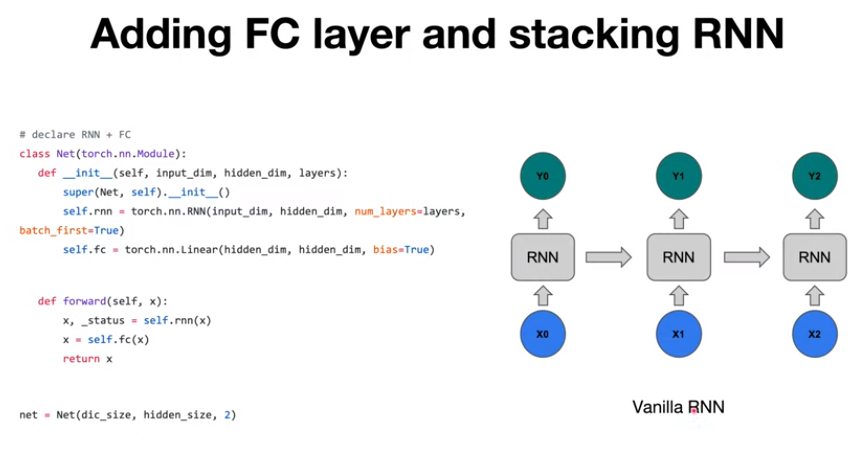
지난번에는 오른쪽 그림과 같이 단순히 RNN cell이 하나인 모델에 대해 다루었다. 하지만 모델이 데이터에 underfitting이 된다면 모델을 조금 더 크게 만들어야 할 수 도 있다.
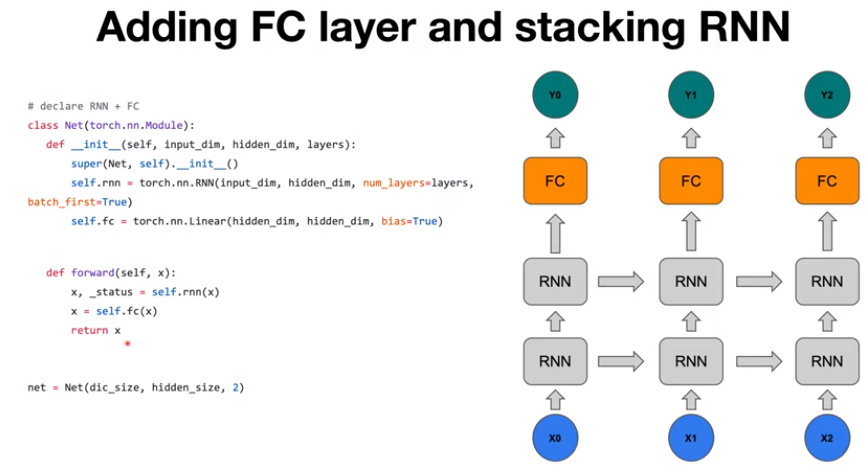
모델을 다양하고 크게 만들수 있지만, 여기서는 간단하게 stacking 하고 fully connected layer를 추가하는 부분에 대해 다루어본다. 그림 왼쪽의 코드를 그림으로 표현하면 오른쪽과 같다. 모델의 구조를 설명하면 보다시피 RNN을 두 번 통과한 다음 fully connected layer 통과하여 output Y가 출력된다.
코드에서는 먼저 PyTorch의 Module을 상속받은 다음 Net이라는 클래스로 정의한 후, 두 가지 메소드를 정의해준다. 하나는 constructor 인 init 함수이고 다른 하나는 forward 함수이다. init 함수는 그 모듈이 내부적으로 어떤 하위 모듈을 쓰는지(여기서는 Net이라는 상위 모듈이 rnn과 fc라는 하위 모듈을 사용) 정의해주는 함수이다. 그리고 forward에서는 정확히 x라는 input을 넣고 network를 계산할 때 어떻게 계산할지에 대한 정의를 내려주는 부분이다. 위의 코드에서는 rnn을 한번 거친 후(특히 위의 코드에서는 Net(dic_size, hidden_size, 2) 이기 때문에 layer가 두 개로 구성된 RNN을 통과), 마지막으로 Linear 모듈(fully connected)을 통과하여 output이 나오게 된다.

다음은 대부분이 이전에 살펴본 코드와 유사하다. 먼저 loss를 CrossEntropyLoss로 정의해주고 Adam optimizer를 사용한다. 그리고 training loop를 100번 돌게되는데, gradient가 매 루프마다 항상 reset이 되도록 zero_grad()를 해주고, 준비한 input data x를 net에 넣어서 output을 받아온다. 그 후 이전에 정의했던 CrossEntropyLoss로 모델의 output과 true_label을 비교하여 loss 값을 구해준다. 그리고 loss.backward() 라는 함수를 진행하면 gradient 값들이 계산되고 optimizer.step()을 실행하면 방금 전에 구했던 gradient 값들을 이용하여 optimizer에 넣었던 network의 파라미터들을 업데이트하게 된다.
마지막으로 아래의 코드들은 모델이 예측한 결과물을 해석하는 부분이다. argmax()를 통해 prediction 확률이 가장큰 결과값들을 불러오고 예측값들을 저장하게 된다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 11-4 RNN timeseries (0) | 2022.03.16 |
|---|---|
| [Pytorch] 11-2 RNN hihello and charseq (0) | 2022.03.14 |
| [Pytorch] 11-1 RNN basics (0) | 2022.03.03 |
| [Pytorch] 11-0 RNN intro (0) | 2022.03.03 |
| [Pytorch] 09-4 Batch Normalization (0) | 2022.03.03 |



