
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Deep learning
- 홍콩과기대김성훈교수
- 정렬
- classifier
- loss
- rnn
- Cross entropy
- 파이토치
- 스택
- Hypothesis
- 알고리즘
- 머신러닝 기초
- 딥러닝
- Softmax
- Python
- 머신러닝
- BAEKJOON
- MSE
- 자연어처리
- tensorflow
- pytorch
- AI
- 강의자료
- machine learning
- Natural Language Processing with PyTorch
- 파이썬
- DynamicProgramming
- DP
- 강의정리
- 백준
- Today
- Total
개발자의시작
[Pytorch] 09-4 Batch Normalization 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이 chapter에서 살펴볼 내용은 다음과 같다.
- Gradient Vanishing/Exploding
- Internal Covariate Shift
- Batch Normalization
- Code: mnist_batchnorm
Gradient Vanishing/Exploding
- Gradient Vanishing
Gradient Vanishing은 sigmoid()와 같은 함수를 사용할 때 발생하는 문제로 gradient가 너무 작아져 소멸하게 되는 문제.
- Gradient Exploding
Gradient Exploding은 Gradient Vanishing과 반대되는 개념으로 gradient가 너무 커져서 발생하는 문제.

위의 그림과 같이 Deep neural network가 있을때, 이 newwork를 학습하기 위해서는 loss를 계산하고 이 loss로부터 gradient를 앞단까지 계산하며 전파를 시키며 업데이트를 한다. 이때 gradient vanishing 문제는 gradient가 앞단으로 전파되면서 너무 작아지는 문제이고, 반대로 gradient exploding 문제는 중간 중간 미분을 계산할때 값이 너무 커지는 문제이다. gradient vanishing/exploding 문제가 발생하면 deep neural network 학습이 어려워진다.
이와 같은 문제들을 해결하기위한 방법들은 다음과 같다.
- Change activation
activation 함수를 바꿔주는 방법이 있다. 예들들어 sigmoid 함수가 vanishing gradient 문제가 발생해 ReLU 함수로 변경하여 이를 해결했다.
- Careful initialization
weight를 initialization 할 때 초기화를 잘 하는 것이 하나의 해결책이 될 수 있다.
-Small learning rate
이는 gradient exploding 문제에 대한 해결책으로 learning rate를 굉장히 작은 값으로 사용하면 어느정도 완화시킬 수 있다.
위의 방법들은 간접적인 방법으로 조금 더 직접적인 방법에 대해 알아본다.
Batch Normalization
batch normalization을 사용하면 gradient vanishing/exploding 문제를 완화할 뿐만 아니라 전체 학습과정이 stable해진다. 또한, dropout과 같은 regularization 효과, 학습속도 향상 등의 이점이 있다.
Internal Covariate Shift

Batch normalization 이전에 Internal Covariate Shift에 대해 이해할 필요가 있다. covariate shift는 neural network를 학습할때 train set과 test set의 분포에 차이가 있다는 것이다. 이 분포의 차이가 문제를 발생시킨다는 것이 covariate shift의 개념.
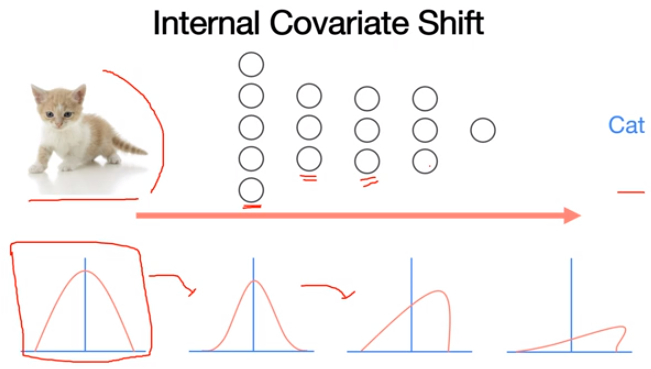
이미지가 주어지고 이것이 "고양이"인지 분류하는 neural network 모델이 있다고 가정한다. 입력 train set이 들어왓을때 "고양이"인지 아닌지 loss를 계산하게 되고 backpropagation을 통해 network들을 업데이트한다. 이런상황에서 internal covariate shift가 발생한다. train set에는 여러 종류의 "고양이"데이터들이 있을 것이고 대충 왼쪽 아래의 분포를 가지고 있다고 가정한다. 학습을 하면서 forward하고 backward를 하는 과정을 거치는데, 첫 번째 layer에서 covariate shift가 발생했다고 하면 분포의 변화가 발생한다. 두 번째 layer를 통과하면서도 마찬가지로 분포의 변화가 발생한다. 이처럼 input과 output의 분포가 바뀌게 되는것이 internal covariate shift인데, 결국에는 layer마다 covariate shift 문제가 발생하게 된다. layer가 많아질 수록 이런 문제가 더 많이 발생하게 된다.

batch normalization의 개념은 매우 간단하다. internal covariate shift를 해결하기 위해서 각 layer들 마다 normalization하는 layer를 둬서 변형된 분포가 나오지 않도록 normalization하는 것이다. 논문에 발표된 알고리즘을 살펴보면, 한개의 배치(ex. 8)가 들어왔을 때 배치사이즈들의 mean과 variance를 계산하고 μ와 σ를 통해 normalization을 해주게 된다. 여기서 ε은 문모가 0이 되지 않도록 방지하는 아주 작은 값이다. normalied 결과에 γ와 β라는 scale과 shift transform을 적용하는데, batch normlization으로 계속해서 normlizing하면 activation function의 non-linearity 같은 성질을 잃게되는 것을 완화시켜주기 위해 사용한다. γ와 β는 학습을 반복적으로 진행하면서 같이 학습되는 trainable한 값이다.
Code:

앞서 dropout에 관해 살펴볼때 평가시에는 model.eval() 사용후 평가해야한다고 했다. BatchNorm을 사용하기 위해서도 마찬가지 이다.
어떤 네트워크가 학습이 끝났다고 가정하고, 이 상황에서 inference(test)를 할때 어떤 문제가 발생하는지 살펴본다. test를 하기위해 데이터 x가 있다고 가정할 때, Neural Network에 넣어서 test를 진행한다. 이때 batch normalization layer를 만나면 평균과 분산 값을 계산하게 된다. 이를 사용해서 normailization을 계산해서 ^x를 구하게 되고, γ와 β를 사용해서 batch normalization을 적용하게 된다. 이때 발생할 수 있는 문제로 x가 변경된다면 평균과 분산의 값이 전혀 다른 값이 나올 수 있다. batch 사이즈가 8이라고 할때 8개의 데이터로 구성된 데이터가 있다. 이때 평균과 분산을 구할 수 있는데, 이때 마지막 두개의 batch를 다른 데이터로 변경한다고 한다. 이 경우 평균과 분산의 값이 달라지게 되고, 이전에 같은 데이터(6개의 batch)에 대해서 다른 평균과 분산 값이 적용되게 된다.

'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 11-1 RNN basics (0) | 2022.03.03 |
|---|---|
| [Pytorch] 11-0 RNN intro (0) | 2022.03.03 |
| [Pytorch] 09-3 Dropout (0) | 2022.01.17 |
| [Pytorch] 09-2 Weight initialization (0) | 2022.01.17 |
| [Pytorch] 09-1 ReLU (0) | 2022.01.14 |



