
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- DP
- rnn
- tensorflow
- machine learning
- Deep learning
- 머신러닝 기초
- classifier
- 정렬
- MSE
- AI
- Python
- BAEKJOON
- DynamicProgramming
- 알고리즘
- 머신러닝
- 홍콩과기대김성훈교수
- Natural Language Processing with PyTorch
- 파이썬
- 자연어처리
- 스택
- loss
- Cross entropy
- Softmax
- 백준
- 파이토치
- 강의자료
- Hypothesis
- pytorch
- 딥러닝
- 강의정리
- Today
- Total
개발자의시작
[Pytorch] 11-1 RNN basics 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
이번 chapter에서는 RNN(Reccurent neural network)을 pytorch에서 어떻게 구현하는지에 대해 살펴본다.
먼저 pytorch에서 RNN을 실행하는 코드를 소개하고 간단한 예제를 살펴본다.
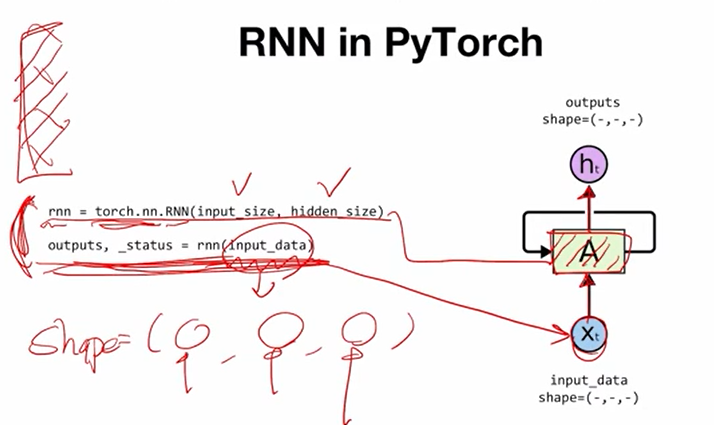
pytorch에서 RNN을 구동하기 위해서는 위 그림에서 보이는 두 줄이 전부이다. 변수 rnn에 torch.nn에 있는 많은 네트워크 중에서 RNN을 불러온다. 이때 두 개의 integer를 파라미터 입력으로 받는데, 이들이 각각 무엇을 의미하는지는 조금 뒤에서 다시 설명한다. 아랫 줄에서는 위에서 선언한 rnn에 입력하고자 하는 데이터 input_data를 입력해주는 부분이다. 이때 input_data는 세 개의 차원을 가지는 tensor로 정의되는데, shape은 위의 그림과 같으며 각각이 무엇을 의미하는 지도 다시 설명한다. 여기까지 살펴보면 pytorch에서 rnn 구동은 굉장히 간단하다. 윗줄을 cell A를 선언하는 과정이라고 본다면 아랫줄은 가지고 있는 데이터 Xt를 cell A에 넣고 그 결과물로 ht로 반환받는 과정이라고 볼 수 있다. 그리고 이 두줄 이외에 생략된 코드들은 단순히 가지고 있는 데이터를 rnn에 입력할 수 있는 tensor의 형태로 만들어주는 과정에 불과하다. 다만 대부분의 deep learning framework들이 그러하듯 pytorch 역시 정해진 규칙에 맞춰 조작해줘야만 원하는 결과를 받을 수 있다.

간단한 예시를 통해 pytorch에서 rnn을 어떻게 구현했는지를 살펴본다. 이 예시는 단어 "hello"를 rnn에 입력하는 과정이다. 이 단어를 구성하는 문자를 모델이 인식할 수 있도록 vector로 치환해서 rnn에 전달해주게 된다. "h"라는 문자 형태로 입력하게 되면 모델이 알아들을 수 없으니 vector의 형태로 만든다. 여기서는 one-hot encoding을 사용하는데, one-hot encoding은 단어를 구성하는 문자들을 사전식으로 나열하여 사전의 개수만큼 벡터를 만들고 각각의 문자의 index에 해당하는 자리를 1로 켜고 나머지를 0으로 끄는 방식이다. 여기서는 h가 맨 처음 나왔기 때문에 첫 번째 index만 1로 나머지는 0으로 표현한다. "h"라는 하나의 문자를 표현하기 위해서는 4개의 차원을 가지는 vector가 필요한 상황이다. 다른 문자들 역시 마찬가지이다. 이렇게 4개의 차원을 input으로 받는다라는 의미로 input_size를 선언하게 되는데, 여기서는 4차원을 사용하기 때문에 input_size는 4로 정의된다. 지금은 one-hot encoding을 사용하지만, h를 표현하기 위해서 word embedding 같은 것을 사용하는 경우에는 embedding vector의 dimension이 input_size가 된다. 그리고 input_size는 cell A가 선언될 때 미리 A에게 사용자가 알려줘야 하는 값이다. A는 미리 4차원의 벡터를 받을 준비를 하게 된다. 이렇게 input_size가 input_data의 dimension 하나로 위치하게 된다. input_data tensor의 dimension 중 하나를 알게 되었다.

다음으로는 hidden state라는 것인데, hidden state는 input data 보다는 output date와 관련된 내용이다. output data로 몇 개의 차원을 가진 vector를 출력받을지 결정해주는 과정이다. 즉, 어떤 vector size의 출력을 원하냐에 따라 hidden size를 정해주면 된다. 지금은 2개의 차원을 원한다라고 특별한 의미 없이 선언했지만, 만약에 input을 통해서 추론할 수 있는 감정의 개수가 여러 개라면 감정의 개수가 hidden size의 개수가 될 것이다. 예컨대 슬픔, 기쁨, 분노 중 한 가지를 추론해야 한다면 hidden size는 3이 될 것이다. 위의 그림에서 볼 수 있듯, output size의 dimension이 2가 된다는 것을 A를 선언하는 과정에서 미리 알려주는 것이다. 위에서 input dimension을 받았다면, 지금은 output dimension 몇을 내놔야 한다는 것을 알려주게 되는 것이다. 정리해보면 input이 4차원짜리 vector가 들어가게 되고 나가는 것은 2차원짜리 vector가 나온다.
hidden state라는 표현에 대해 살펴본다. hidden state는 말 그대로 "숨겨진 상태"인데, cell A의 입장에서 output은 외부로 노출되는 값이 된다. 하지만 바깥으로 내놓지 않고 숨겨진 상태로 다음번 sequence input에 같이 전달해주는 값이 존재하는데, 이것을 hidden state라고 한다. hidden size를 정의한다라는 것은 hidden state의 vector dimension을 정의하는 것인데, 이것이 어떻게 output size와 동일한 값을 가지게 되는지 의문을 제기할 수 있다. 이것은 RNN cell의 내부 구조를 살펴보면 간단히 이해할 수 있다.
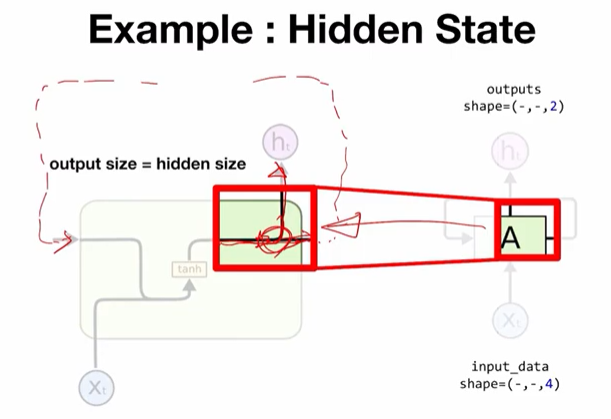
위 그림은 cell A를 자세히 표현한 것이다. 분기되는 지점이 있는데, 출력 직전에 똑같은 값이 두 개의 가지로 갈라진다. 하나는 output으로 나가게 되고 하나는 hidden state로 출력된다. hidden state가 외부로 나가지 않고 그대로 돌아서 다음번 input으로 유입되게 되는 구조로 설계되어 있다. 이러한 설계이기 때문에 hidden state의 size와 output size는 같은 값을 가지게 된다.
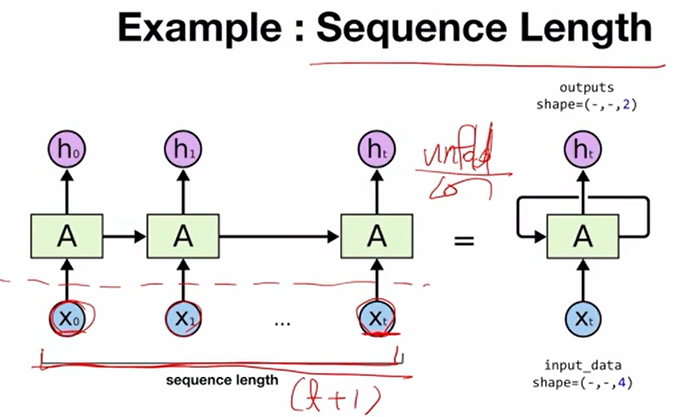
다음은 RNN의 특징인 sequence data를 입력받는다 라는 점으로부터 생긴 sequence length라는 dimension이다. 우측 그림이 일반적으로 RNN을 표현하는 그림인데, 이것을 왼쪽과 같이 펼쳐보면 x0부터 xt까지가 데이터를 넣는 부분이다. x0부터 xt까지 순서대로 t+1개의 길이를 가진 sequence가 생기게 되는데 이것이 sequence length이다.
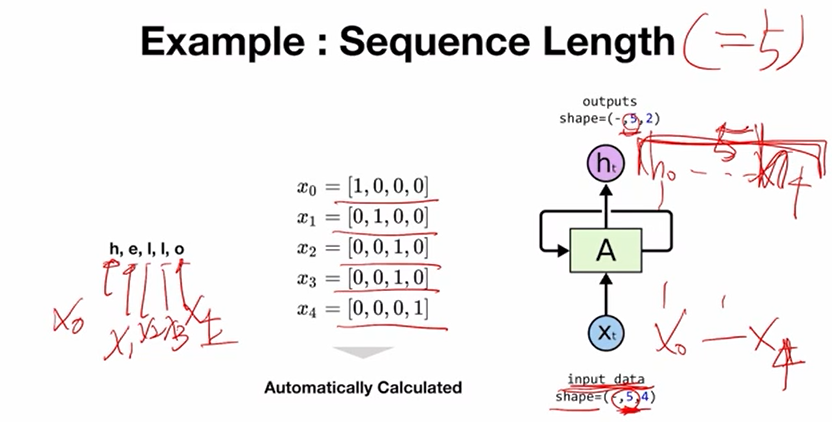
sequence length를 위에서부터 예로 들었던 "hello"에 적용해보면, "hello"는 5개의 문자를 갖고 sequence length가 5가 된다. "h"가 x0이며 각각이 x1부터 xt까지가 된다. 모델에 입력될 때는 각각의 one-hot encoding의 vector들로 변환되어 모델에 들어가게 된다. pytorch의 놀라운 점은 sequence length를 사용자가 모델에 직접 알려주지 않아도 모델이 sequence length를 자동으로 파악한다는 점이다. 그래서 입력으로 사용된 데이터의 length가 5라면 input data의 shape을 pytorch가 자동으로 인식하여 별도로 지정해주지 않아도 된다. 다만 input data만 잘 만들어주면 그다음은 알아서 진행해주는 것이 pytorch의 매력이라 할 수 있다. 그리고 당연하게도 input data가 5개의 sequence length를 갖는다면, 각각에 맞추어 h0부터 h4가 나올 것이고 5개의 sequence length가 output tensor의 dimension으로 반영된다.

마지막 한 자리가 남았는데 마지막 자리는 batch size이다. RNN이전에 다른 NN에서도 batch라는 개념은 있었는데, RNN에서도 마찬가지로 여러 개의 데이터로 하나의 batch로 묶어서 모델에게 학습시킬 수 있다. 여기서는 one-hot encoding에서 선언한 "h", "e", "l", "o" 4개의 문자로 만들어진 수많은 단어 중에서 3개의 단어를 묶어서 하나의 batch로 구성하고 이것을 모델에게 전달해주는 과정을 나타낸다. 또 놀라운 점은 batch size 역시 사용자가 모델에게 직접 알려주지 않아도 자동으로 모델에서 batch size를 파악하게 된다. 따라서 직접 입력해서 모델에게 알려주지 않아도 되고 단지 input data만 잘 구성해주면 충분히 학습을 진행할 수 있다.

전체 코드를 살펴보면, 앞서 말한 것과 같이 3개의 단어를 하나의 batch로 구성해서 input data로 만들고, input data를 RNN에 입력해주는 코드이다. 사실 RNN을 구동하는 코드는 아래 두 줄이 전부이다. 그리고 위의 부분은 input data tensor를 만들어주는 과정이고, RNN을 선언하기 위한 input size와 hidden size를 정의하는 부분과 import 하는 부분이다. 실제로 RNN 구동은 두줄이고 나머지 대부분은 데이터 정제이고, 그중에서도 밑줄 친 부분은 위에서 만들어진 numpy로 만든 tensor를 torch에서 사용하는 tensor로 바꿔주는 과정이다. numpy에서 tensor로 만드는 부분이 중요한데, 3개의 데이터를 batch로 가지고 있고 각각의 데이터 안에서는 5개의 length를 가진다. 한 batch의 한 sequence의 각각의 원소들은 one-hot encoding에 의해 4개의 차원을 가지는 벡터이다.(input size=4) 따라서 input data는 (3, 5, 4) 형태의 shape을 가지는 tensor가 된다. hidden size는 (3, 5, 2) 형태의 shape을 가지는 tensor가 될 것이다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 11-3 RNN - longseq (0) | 2022.03.15 |
|---|---|
| [Pytorch] 11-2 RNN hihello and charseq (0) | 2022.03.14 |
| [Pytorch] 11-0 RNN intro (0) | 2022.03.03 |
| [Pytorch] 09-4 Batch Normalization (0) | 2022.03.03 |
| [Pytorch] 09-3 Dropout (0) | 2022.01.17 |



