
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Natural Language Processing with PyTorch
- MSE
- 머신러닝 기초
- 알고리즘
- 홍콩과기대김성훈교수
- 정렬
- machine learning
- 딥러닝
- loss
- Python
- DynamicProgramming
- 강의자료
- Cross entropy
- pytorch
- 머신러닝
- 강의정리
- Hypothesis
- 자연어처리
- BAEKJOON
- Deep learning
- 스택
- rnn
- 백준
- classifier
- Softmax
- 파이토치
- DP
- AI
- 파이썬
- tensorflow
- Today
- Total
개발자의시작
[Pytorch] 03 Deeper Look at GD 본문
글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
이전 챕터보다 더 간단한 hypothesis를 사용한다.

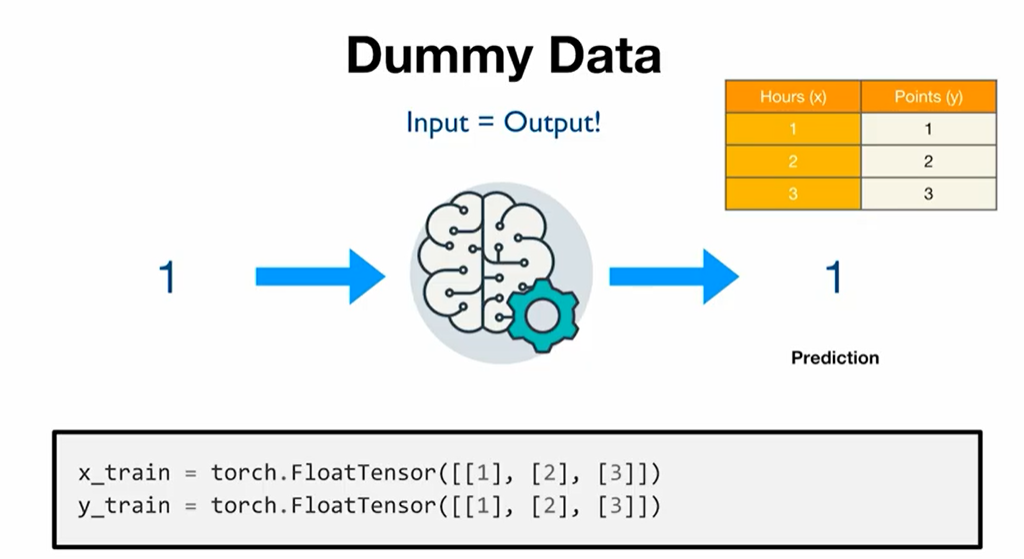
이 데이터는 입력과 출력이 동일하므로 W = 1이 가장 좋은 값이 된다.( H(x) = x가 가장 정확한 모델 )
여기서 모델의 좋고 나쁨을 어떻게 평가할 수 있을까?
cost function은 모델의 예측 값이 실제 데이터와 얼마나 다른지를 나타내는 값으로, 잘 학습된 모델일수록 낮은 cost를 갖는다. 위 모델에서는 W=1 일 때, cost=0이며, W가 1에서 멀어질수록 cost가 높아진다.

Linear Regression 에서 쓰이는 cost function은 Mean Squared Error이며 MSE라고 줄여서 표현한다. MSE는 말 그대로 예측값과 실제 값의 차이를 제곱한 평균을 나타낸다.

cost function이 예측값과 실제값의 차이를 나타내므로, 학습의 목적은 cost function을 최소화 하는 것이다. cost를 최소화하기 위해서는 기울기가 음수일 때는 W가 더 커져야 하고 기울기가 양수일 때는 W가 더 작아져야 한다.

Gradient
gradient를 계산하려면 미분을 해야하는데, cost function은 결국 W에 대한 2차 함수이므로 간단한 미분 공식을 통해 계산할 수 있다.

Gradient Descent
gradient descent는 Pytorch로 간단하게 구현할 수 있다.


torch.optim으로도 gradient descent를 할 수 있다.
- 시작할때 optimzer 정의
- optimzer.zero_grad() 로 gradient를 0으로 초기화
- cost.backward()로 gradient 계산
- optimizer.step()으로 gradient descent

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import torch
import numpy as np
#데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
#모델 초기화
W = torch.zeros(1, requires_grad=True)
#optimizer 설정
optimizer = torch.optim.SGD([W], lr=0.15)
nb_epochs= 10
for epoch in range(nb_epochs +1):
# H(x) 계산
hypothesis = x_train * W
# cost gradient 계산
cost = torch.mean((hypothesis - y_train) ** 2)
print("Epoch {:4d}/{} W: {:.3f}, Cost: {:.6f}".format(epoch, nb_epochs, W.item(), cost.item()))
#cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
|
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 04-2 Loading Data (0) | 2021.11.30 |
|---|---|
| [Pytorch] 04-1 Multivariate Linear Regression (0) | 2021.11.30 |
| [Pytorch] 02 Linear regression (0) | 2021.11.30 |
| [Pytorch] 01-2 Tensor Manipulation 2 (0) | 2021.11.26 |
| [Pytorch] 01-1 Tensor Manipulation 1 (0) | 2021.11.26 |



