
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Cross entropy
- 정렬
- 파이토치
- 스택
- 딥러닝
- 백준
- loss
- 머신러닝
- 강의자료
- Python
- MSE
- Softmax
- machine learning
- AI
- 머신러닝 기초
- pytorch
- classifier
- 홍콩과기대김성훈교수
- 자연어처리
- tensorflow
- BAEKJOON
- Deep learning
- 알고리즘
- Natural Language Processing with PyTorch
- 강의정리
- rnn
- Hypothesis
- DP
- DynamicProgramming
- 파이썬
- Today
- Total
개발자의시작
[Pytorch] 05-1 Logistic Regression 본문
이 글은 모두를위한딥러닝 시즌2 https://github.com/deeplearningzerotoall/PyTorch 을 정리한 글입니다.
GitHub - deeplearningzerotoall/PyTorch: Deep Learning Zero to All - Pytorch
Deep Learning Zero to All - Pytorch. Contribute to deeplearningzerotoall/PyTorch development by creating an account on GitHub.
github.com
( http://hunkim.github.io/ml/ 참고)
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io
Logistic Regression
- Clasification : 특정한 기준을 가지고 분류하는 것.(대표적인 분류 문제: spam detection: spam or ham, facebook feed: show or hide)
- 이를 기계적으로 학습하기 위해서 0 또는 1로 encoding을 한다. (ex. spam detection: spam(1) or ham(0), facebook feed: show(1) or hide(0))
Binary Classification
공부한 시간에 따라 시험에 합격하는지 불합격하는지 분류하는 모델이 있다고 가정한다.

- 위와 같은 데이터 형태가 있다고 가정할 때, 마치 이전의 linear regression과 비슷한 형태를 보인다.

linear regression과 같은방식으로 기울기 W를 설정할 경우 문제가 발생한다. 50시간 공부한 경우 합격에 해당하는데, 이상태로 학습하게 되면 합격과 불합격을 구분하는 새로운 기울기를 구하게 되고 원래 합격인 대상은 불합격으로 인식될 수 있다.

또 다른 문제로, classification의 경우 0과 1 사이의 값이 나와야 하지만, H(x) = Wx+b 와 같은 hypothesis를 가지게 되면 결과 값이 0보다 작거나 1보다 훨씬 큰 값을 가질 수 있다.

이러한 문제를 해결하기 위해 사람들은 hypothesis를 0~1 사이로 압축해 줄 수 있는 어떤 형태의 함수가 있으면 좋을 것이라는 생각을 했다. 어떤 함수 g(z)는 z의 값에 상관 없이 대략 0~1 사이의 값으로 만들어 주는 함수에 해당. g(z) 함수를 찾다가 생각한 것이 바로 sigmoid 함수이다.


그래서 Logistic classification의 Hypothesis는 위와 같이 H(X)로 주어지며, sigmoid 함수를 사용한다. 이것이 logistic classification의 가장 중요한 함수이다.
Linear Regression의 Cost

linear regression의 cost function은 위와 같이 나타낼 수 있다. 여기서 H(x)는 = Wx+b이다.

x의 값에 따른 cost를 그래프로 나타내면 각각의 hypothesis는 위와 같이 나타 낼 수 있다. gradient descent 알고리즘을 쓸 경우 H(x)=Wx+b는 최소 지점을 찾을 수 있다. 하지만 sigmod 함수를 사용한 경우 특정 지점들은 편평한 형태를 가져 경사 하강을 더 이상 진행하지 못하는 경우가 발생한다.(Local Minimum 문제) 모델을 잘 학습시키기 위해서는 global mimum을 찾아야 한다. Hypothesis가 바뀌었기 때문에 cost function도 바꿔줄 필요가 있다.((국소 최적해 문제를 해결해야함)

결과적으로 위와 같은 cost function을 사용한다. cost 함수는 어떤 비용의 평균이기 때문에 값들을 합한 후 개수(m)로 나누어준다. 그리고, 두 가지 케이스로 나누어 정의한다. y가 1일 경우 -log(H(x)), y=0 일 경우 -log(1-H(x))이다.
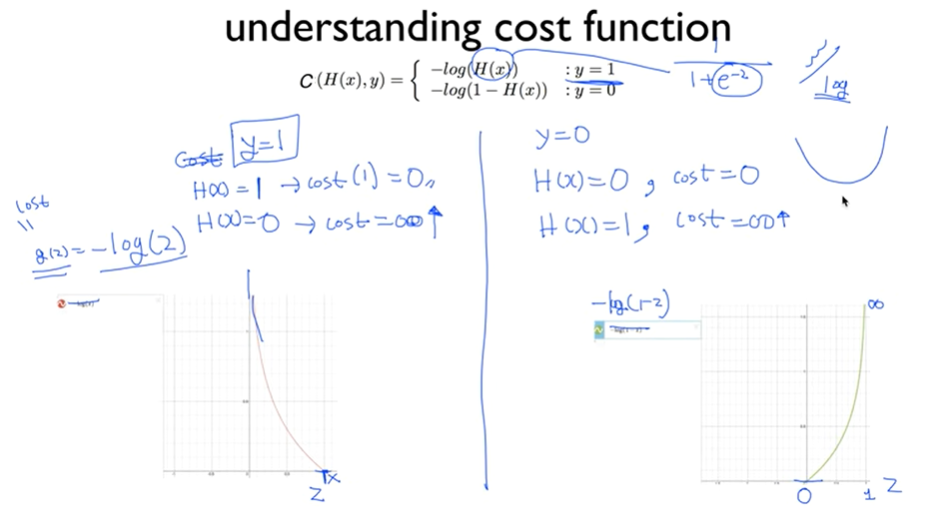
이해를 돕기 위한 설명으로, 정의한 Hypothesis는 exponential function을 사용하고 이는 구부러진 형태의 결과를 출력한다. 이를 상쇄시키기 위해 log 함수를 사용한다. cost를 두 가지 케이스로 나누어 정의한다.
※ y=1일 때, H(x)가 1로 맞는 경우(H(x)가 y와 같은 경우) cost는 0이 된다. 반면 H(x)가 0으로 틀린 경우(H(x)가 y와 다른 경우) cost가 굉장히 큰 값이 된다.
※ y=0일 때, H(x)가 0으로 맞는 경우(H(x)가 y와 같은 경우) cost는 0이 된다. 반면 H(x)가 1로 틀린 경우(H(x)가 y와 다른 경우) cost가 굉장히 큰 값이 된다.
결과 적으로 두 개의 케이스를 하나로 합치면 하나의 매끄러운 그래프를 가질 수 있고, linear regression에서와 같이 경사 하강법을 통해 최소 지점(global minimum)을 찾을 수 있다.
정리하면 cost function은 다음과 같이 정의할 수 있다. if condition을 없애 하나의 식으로 표현할 수 있다.


그다음 단계로 cost가 주어지면, cost를 minimize 하는 것인데, 경사 하강법을 사용하여 최소 지점을 찾는다. 이 역시 미분을 통해 처리하는데, 미분 값에 따라서 현재 지점에서 기울기가 0에 가까운 쪽으로 이동한다.
'머신러닝(machine learning)' 카테고리의 다른 글
| [Pytorch] 06-1 Softmax Classification (0) | 2021.12.28 |
|---|---|
| [Pytorch] 05-2 Logistic Regression 2 (0) | 2021.12.23 |
| [Pytorch] 04-2 Loading Data (0) | 2021.11.30 |
| [Pytorch] 04-1 Multivariate Linear Regression (0) | 2021.11.30 |
| [Pytorch] 03 Deeper Look at GD (0) | 2021.11.30 |



